Almacenamiento y estructura de archivos
Medios fisicos de almacenamiento
Los medios de almacenamiento se clasifican por la velocidad de acceso a sus
datos, por el coste de adquisicion del medio por unidad de datos y por la
fiabilidad del medio.
Medios
+ Cache: Esta es la forma de almacenamiento mas rapida y costosa.
+ Memoria principal: Es el medio de almacenamiento utilizado para los datos
disponibles para operar con ellos. En ella operan las instrucciones de la
maquina de proposito general. Su contenido suele perderse si se cae el sistema
o se va la luz.
+ Memoria flash: Es aquella memoria de solo lectura programable y borrable
electronicamente -EEPROM. Esta memoria soporta los fallos electricos
y la lectura, sin embargo los datos solo su escritura es posible solo una
vez y para sobreescribir se debe borrar simultaneamente un banco de memoria.
Su problema es que permite un numero limitado de borrados.
+ Discos magneticos: Este es el principal medio de almacenamiento de datos
a largo plazo.
+ Almacenamiento optico: Esta es la
forma mas popular de almacenamiento y es aquella denominada memoria de solo
lectura en disco compacto-CDROM.
En este los datos se almacenan en un disco por medios opticos y se leen mediante
un laser.
+ Almacenamiento en cinta: Este medio
se utiliza principalmente para copias de seguridad. Su acceso es muy lento
ya que se hace de manera secuencial, no
como en el caso de los discos magneticos cuyo acceso es directo.
Jerarquia de medios de almacenamiento
Los diferentes medios de almacenamiento
pueden organizarse en una jerarquia de acuerdo con su velocidad y su coste.
Los de nivel
superior son de alto costo pero rapidos. A medida que se desciende por la
jerarquia, el coste por bit disminuye, mientras que el tiempo
de acceso aumenta.
cache
memoria principal
memoria flash
disco magnetico
disco optico
cintas magneticas
A la memoria cache y principal, por ser medios
de almacenamiento mas rapidos, se les denomina almacenamiento primario. Los
medios del siguiente
nivel de la jerarquia como los discos magneticos se les conoce como almacenamiento
secundario. Los niveles inferiores de la jerarquia como los
las cintas magneticas se les denomina almacenamiento terciario.
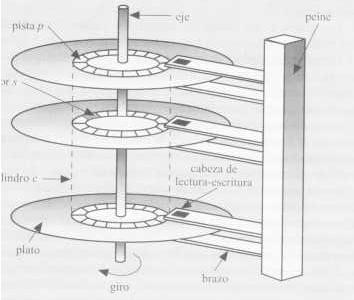
Discos magneticos
Estos proporcionan la parte principal del almacenamiento secundario de los
sistemas inform�ticos modernos.
Caracteristicas
- Cada plato del disco tiene una forma circular plana
- Sus dos superficies estan cubiertas por un material magnetico
- En estas superficies se graba la informacion
- Los platos estan hechos de metal o de vidrio rigido
- Los platos tambien estan cubiertos con un material magnetico
- Se cuenta con un motor que se encarga de girar el disco
- Se tiene una cabeza de lectura y escritura ubicada justo encima
- La superficie del disco se divide en pistas
- Las pistas se dividen en sectores
- Un sector es la unidad minima de informacion que puede leerse o escribirse
en el disco
- Los sectores varian desde los 32 hasta los 4096 bytes; por lo general son
de 512 bytes
Medidas del rendimiento de los discos
-El tiempo de acceso: es el tiempo transcurrido desde que se formula una solicitud
de lectura o escritura hasta que comienza la transferencia de los datos.
-El tiempo de busqueda: es el tiempo que se gasta para volver a ubicar el
brazo.
-El tiempo medio de busqueda: es la media de los tiempos de busqueda medido
en una sucesion de solicitudes aleatorias
-El tiempo de latencia rotacional:es el tiempo que se pasa esperando a que
el sector al que hay que tener acceso aparezca bajo la cabeza.
-Velocidad de transferencia de datos: es la velocidad a la que se pueden recuperar
o guardar datos en el disco.
-El tiempo medio entre fallos: es una medida de fiabilidad del disco. Esta
no es mas que la cantidad de tiempo que se espera que el sistema funcione
de manera continua sin tener ningun fallo.
Raid
Los discos han ido reduciendo de tamano y
de precio en los ultimos anos, por lo tanto resulta posible adjuntar gran
numero de discos. Nos sale mejor que comprar un gran disco muy costoso.
El tener varios discos nos permite mejorar la velocidad con la que se pueden leer o escribir los datos, si estos trabajan en paralelo.Podemos mejorar la fiabilidad del almacenamiento. Podemos guardar informacion repetida en varios discos. Si uno falla, no se pierden los datos.
Estas tecnicas se denominan disposicion redundante de discps independientes RAIDs
Redundancia
Es la solucion del problema de la fiabilidad, en donde se guarda informacion
que normalmente no se utiliza pero que puede utilizarse en caso de fallo de
un disco. Para asi reconstruir la informacion. Esta tecnica se denomina creacion
de imagenes.
un disco logico se compone de dos fisicos. En ambos se realiza el proceso de escritura. Primero en una ---> luego en la otra.
Paralelismo
Nos permite mejorar el rendimiento. Con la creacion de imagenes de los discos,
la velocidad de lectura se duplica,dado que las solicitudes pueden enviarse
a cualquiera de los discos
Los
archivos se organizan logicamente como secuencias de registros. Estos registros
se corresponden con los bloques del disco. Aunque los bloques
son de un tamano fijo determinado por las propiedades fisicas del disco y
por el sistema operativo, los tamanos de los registros varian.
En este esquema desde el comienzo se cuenta con un registro con un tamano predefinido donde los primeros n bytes del archivo son para el primer registro, los n bytes siguientes son para el segundo... etc.
Problemas
1. Es dificil borrar un registro de esta estructura; se debe rellenar el espacio
con otro registro o colocar alguna marca especial para los borrados de modo
que puedan pasarse por alto.
2.
En dado caso que se trate de insertar un registro con una longitud diferente
a la predefinida, se podra presentar el caso de que el registro se guarde
en un bloque y parte en otro. Este caso es improbable.
Cuando se borra un registro se pueden desplazar secuencialmente el registro situado a continuacion al espacio ocupado anteriormente por el registro borrado y hacer lo mismo con los demas registros hasta que todos los registros situados a continuacion del borrado se hayan desplazado hacia delante.
-
Este enfoque necesitaria desplazar un gran numero de registros.
- Lo mas simple seria mover el ultimo registro al espacio ocupado por el registro
borrado.
Como las inserciones son mas frecuentes, lo mejor es dejar el espacio libre y cuando llegue una nueva insercion, tomar ese espacio disponible. Para poder implementar esta solucion, debemos colocar al comienzo del archivo una cabecera. En esta vamos a colocar cierta informacion sobre el archivo pero, por ahora uno de los campos sera la direccion donde se encuentra el primer registro cuyo contenido fue borrado. Ademas, este primer registro tiene informacion de cual es el siguiente registro disponible y asi sucesivamente. Todos estos registros borrados, forman una lista enlazada que se denomina lista libre. Al insertar un nuevo registro en el lugar indicado por la cabecera, se cambia la informacion que esta contiene de modo que apunte al siguiente registro disponible. Si no hay espacio, se anade el nuevo registro al final del archivo.
Registros de longitud variable
Estos
surgen en los siguientes casos:
- almacenamiento de varios tipos de registros en un mismo archivo
- tipos de registro que permiten longitudes variables para uno o mas campos
- tipos de registro que permiten campos repetidos
Los siguientes son esquemas de representacion:
Representacion en cadenas de bytes
1.Simbolo
de fin de cadena
Este es un metodo sencillo de implementacion en el cual a los registros de
longitud variable se les adiciona al final un caracter de fin de registro(�).
De este modo vamos a poder guardar cada registro como una cadena de bytes
consecutivos.
Otra forma es guardar la longitud del registro al comienzo de cada registro en lugar de utilizar simbolos para indicar su fin.
Problemas
- No es facil volver a utilizar el espacio ocupado anteriormente por un registro
borrado.
- Si un registro aumenta de tama�o, hay que desplazarlo y esto resulta algo
costoso si se llega a montar en otro registro.
2.Estructura de paginas con ranura
Este esquema contiene una cabecera al principio de cada bloque el cual contiene
la siguiente informaci�n:
- numero de elementos del registro de la cabecera
- el final del espacio vacio del bloque
- un vector cuyas entradas contienen la ubicaci�n y el tama�o de cada registro.
Los
registros reales se ubican de manera secuencial en el bloque, empezando desde
el final del mismo. El espacio libre queda entre el final del vector de la
cabecera y el primer registro. Al insertar un registro, este se ubica al final
del espacio libre y se a�ade a la cabecera una entrada que contiene su tama�o
y su ubicacion. Cuando se borra un registro, a su vector en la posicion que
corresponde a ese registro se le coloca un tama�o de -1 y NULL
a su ubicacion. Todos los registros se desplazan hasta que de nuevo el espacio
vacio quede ubicado entre el vector y el primer registro. Por ultimo se actualiza
el puntero que indica el fin del espacio libre.
Representacion de longitud fija
Otra manera de implementar eficientemente los registros de longitud variable en un sistema de archivos es utilizar uno o varios registros de longitud fija para representar cada registro de longitud variable.
1.El
espacio reservado
Si de antemano sabemos el registro con longitud maxima que puede ingresar
al archivo, y sabiendo que ningun otro sera mayor que este, podremos utilizar
este esquema donde el espacio que no sea utilizado se rellena con un simbolo
especial de valor nulo. Este metodo es util cuando la mayor parte de los registros
son de una longitud cercana a la maxima. En caso de no ser asi, se puede desperdiciar
una candidad significativa de espacio.
2.Los
punteros
El registro de longitud variable se representa mediante una lista de registros
de longitud fija, enlazada mediante punteros. Este esquema lo debemos tratar
de utilizar cuando un registro contenga muchos mas campos que otros.
Este
esquema tiene el problema de que se desperdicia espacio en todos los registros
excepto en el primero de la serie. Para arreglar esto se
permiten en el archivo dos tipso de bloques:
a)Bloque
ancla, el cual contiene el primer registro de cada cadena
b)Bloque de desbordamiento, el cual contiene los registros que no son los
primeros de sus cadenas.
Por lo tanto, todos los registros del interior de cada bloque tienen la misma longitud, aunque no todos los registros del archivo tengan la misma longitud.
Organizacion
de los registros en archivos
Los siguientes esquemas son maneras de organizar los registros en los archivos.
*Organizaci�n
de archivos en mont�culos. En esta organizacion se puede colocar cualquier
registro en cualquier parte del archivo en que haya espacio suficiente. Estos
no estan ordenados.
*Organizacion
de archivos secuenciales. En esta organizacion los registros se guardan en
orden secuencial, basado en el valor de la clave de busqueda de cada registro.
*Organizacion
asociativa (hash) de archivos. Es esta organizacion se calcula una funcion
hash de algun atributo de cada registro. El resultado de la funcion de asociacion
especifica el bloque del archivo en que se debera colocar el registro.
*Organizacion
de archivos en agrupaciones. En esta organizacion se pueden guardar en el
mismo archivo registros de varias relaciones
diferentes. Los registros relacionados de las diferentes relaciones se guardan
en el mismo bloque, por lo que cada operacion de E/S afecta
a registros relacionados de todas esas relaciones.
Organizacion
de archivos secuenciales
Estos estan dise�ados para el procesamiento eficiente de los registros de
acuerdo con un orden basado en una clave de busqueda. Para permitir
la rapida recuperacion de los registros, estos se vinculan mediante punteros.
Cada puntero apunta al siguiente registro segun el orden
indicado por la clave de busqueda. Los registros se almacenan en orden, de
este modo vamos a minimizar el numero de accesos a los bloques.
Problemas
- Es dificil mantener el orden fisico secuencial al insertar o borrar registros
- Es costoso desplazar todos los registros como consecuencia de la insercion
o el borrado de un registro
Para insertar un nuevo registro se debe localizar el registro que precede al que se va a insertar. Si existe un espacio vacio dentro del mismo bloque de ese registro, el registro se insertara ahi. De lo contrario, se insertara en un bloque de desbordamiento.
Indexacion
y asociacion
Un indice para un archivo funciona como el catalogo de libros de una biblioteca.
Donde si se quiere buscar algun libro se busca por el indice deseado. De este
modo, podremos mirar directamente en ese indice sin necesidad de recorrer
completamente todos los libros de la biblioteca.
*Indices
ordenados: Estos indices estan basados en una disposicion ordenada de los
valores
*Indices asociativos (hash): Estos indices estan basados en una distribucion
uniforme de los valores a traves de una serie de cajones. El valor asignado
a cada cajon esta determinado por una funcion de hashing
Tecnicas
de indexacion y asociacion
Existen varias tecnicas de indexacion y asociacion. Ninguna de ellas es mejor.
Sin embargo existen aplicaciones especificas de bases de
datos donde aplicarlas. Cada tecnica debe ser valorada segun los siguientes
criterios:
-Tipos
de acceso: Los tipos de acceso que se soportan eficazmente. Estos tipos podrian
incluir la busqueda de registros con un valor concreto en un atributo, o buscar
los registros cuyos atributos contengan valores en un rango especificado
-Tiempo de acceso: el tiempo que se tarda en buscar un determinado elemento
de daots, o conjunto de elementos, usando la tecnica en cuestion
-Tiempo de insercion: el tiempo empleado en insertar un nuevo elemento de
datos. Este valor incluye el tiempo empleado en buscar el lugar apropiado
donde insertar el nuevo elemento de datos, asi como el tiempo empleado en
actualizar la estructura del indice.
-Tiempo de borrado: Es el tiempo empleado en borrar un elemento de datos.
Este valor incluye el tiempo empleado en buscar el elemento a borrar, asi
como el tiempo empleado en actualizar la estructura del indice.
-Espacio adicional requerido: El espacio adicional ocupado por la estructura
del indice. Como normalmente la cantidad necesaria de espacio adicional suele
ser moderada, es razonable sacrificar el espacio para alcanzar un rendimiento
mejor.
Indices
Ordenados
Indice
primario
Todos los archivos estan ordenados secuencialmente segun el campo clave se
denominan archivos secuenciales indexados. Estos los empleamos en aquellas
aplicaciones que demandan un procesamiento secuencial del archivo completo,
as� como un acceso directo a sus registros.
Indices densos,dispersos y multinivel
* Indice denso: En el cual aparece un registro indice para cada valor de la clave busqueda en el archivo. El registro indice contiene el valor de la clave y un puntero al primer registro con ese valor de la clave de busqueda.

* Indice disperso: Solo se crea un registro indice para algunos de los valores. Al igual que en los indices densos, cada registro indice contiene un valor de la clave de busqueda y un puntero al primer registro con ese valor de la clave. Para localizar un registro se busca la entrada del �ndice con el valor mas grande que sea menor o igual que el valor que se esta buscando.

Apesar de ser mas rapido localizar un registro si se usa un indice denso, aveces es mejor utilizar el esquema de indice disperso para utilizar un espacio mas reducido y un mantenimiento adicional menor para las inserciones y borrados.
* Indices multinivel: Incluso si se usan indices dispersos, el propio indice podria ser demasiado grande para un procesamiento eficiente.
Actualizacion
del indice
Sin importar el tipo de indice que se este usando, los indices se deben actualizar
siempre que se inserte o se borre un registro del archivo.
- Borrado: Primero se busca el indice a borrar. Si el registro borrado era el unico registro con el valor de su clave de busqueda, entonces se borra este valor del indice. Para indices densos el proceso es similar al utilizado para borrar un registro en un archivo. Para indices dispersos, se borra un valor clave sustituyendo su entrada en el indice por el siguiente valor de la clave. Si el siguiente valor de la clave de busqueda tenia ya una entrada, se borra la entrada en lugar de reemplazarla.
- Inserci�n: Primero se realiza una busqueda usando el valor de la clave de busqueda del registro a insertar. Si el indice es denso y el valor de la busqueda no aparece en el indice, el valor se inserta en el indice. Si el indice es disperso y almacena una entrada por cada bloque, no es necesario cambiar el indice a menos que se cree un nuevo bloque. En este caso, el primer valor que aparezca en el nuevo bloque es el valor a insertar en el indice
Indices
secundarios
Un indice secundario sobre una clave candidata es como un indice denso primario,
excepto que los registros apuntados apuntados por los sucesivos
valores del indice no estan almacenados secuencialmente. En este esquema,
debemos usar un nivel adicional de indireccion para implementar los indices
secundarios sobre claves de busqueda que no sean claves candidatas. Los punteros
a estos indices no apuntan directamente al
archivo. En vez de eso, cada puntero apunta a un cajon que contiene punteros
al archivo. Los indices secundarios, mejoran el rendimiento de
las consultas que emplean claves diferentes de la clave de busqueda del indice
primario.
Estos
arboles son una generalizacion de los arboles AVL pero aplicados a los arboles
N-arios. Fueron creados por Bayer y
Mc Creight en 1979 y su nombre nunca fue explicado.
Aca cada
pagina (nodo) en un arbol B de orden:
d -> (contiene)
como maximo 2d claves
(contiene) como minimo d claves
como maximo 2d claves para garantizar que cada pagina se encuentra llena como minimo hasta la mitad.
Respecto
al numero de hijos cada pagina de orden d tiene:
2d + 1 hijos como maximo
d + 1 hijos como minimo
menos en el caso de la raiz que tiene como minimo una clave y por lo tanto 2 hijos.
Sabiendo que d es el grado del arbol, se define un arbol B aquel que:
Cada pagina,
excepto la raiz, contiene entre d y 2d elementos.
Cada pagina, excepto la raiz y las hojas, tiene entre d+1 y 2d +1 hijos
La pagina raiz tiene al menos dos descendientes
Las paginas hojas estan todas al mismo nivel.
Busqueda en Arboles B
1. Tener
en memoria la pagina sobre la cual vamos a trabajar
2. Si esta es diferente de NULL
*Verifica si la clave buscada se encuentra en dicha
pagina (si el numero de claves de esta pagina son muy pequenos
la
buscamos secuencialmente, si no por busqueda binaria)
Si
la clave se encuentra, mensaje de exito
Si
no
- Si
el elemento a buscar es < que la clave1 se localiza en la pagina 0
- Si el elemento a buscar esta entre
clavei < X < clave m se localiza en la paginai
- Si el elemento a buscar es >
que la clavem se localiza en la pagina m
Se
regresa al paso 1
*Error!!! La pagina es igual a NULL, la clave no se encuentra
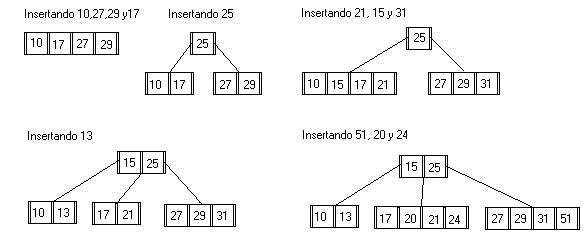
Insercion en Arboles B
Es un proceso sencillo pero complicado con respecto a otros arboles como todas las hojas estan al mismo nivel, cualquier camino desde la raiz hasta una hoja tiene la misma longitud.
Los arboles B crecen de abajo hacia arriba (desde las hojas hacia la raiz)
Proceso
1.
Localizar la pagina donde se debe insertar la clave
Si el numero de elementos de la pagina es menor a
2d (m < 2d).
Se Inserta la clave en el lugar
correspondiente (en orden).
Si
el numero de elementos de la pagina es igual a 2d ( m==2d).
Se divide en dos. Se distribuyen
las m+1 claves equitativamente entre las dos paginas. La clave
del medio sube a la pagina antecesora.
Si esta se llena, se sube y se repite el mismo proceso a o b.
Insertando las siguientes claves en un arbol B de orden 2 el cual se encuentra vacio
10-27-29-17-25-21-15-31-13-51-20-24
Borrado en arboles B
Es una operacion mas complicada que la insercion consiste en quitar claves sin violar los principios del arbol B. En una pagina, excepto la raiz , no puede haber menos de d claves ni mas de 2d claves.
Casos
1. Si la clave a borrar se encuentra en una pagina hoja entonces simplemente se borra
1.1
Si el numero de claves es mayor o igual que el orden del arbol (m >=
d) verificamos m
Termina la operacion
de borrado
1.2 Si no, bajamos la clave adyacente de la pagina antecedente y sustituimos
la clave por la que se encuentre mas a la derecha del subarbol izquierdo
o por la mas a la izquierda del subarbol derecho. es decir, se mantiene asi
m>= d de otra forma fusionar las paginas que son descendientes directas
de dicha clave.
2.
Si la clave a borrar no esta en una pagina hoja
2.1 Debe sustituirse por la clave que se encuentra mas a la derecha en el
subarbol izquierdo o por la que se encuentre mas a la izquierda del subarbol
derecho.
si m >= d, verificamos m. Termina la operacion
de borrado
sino, se baja la clave adyacente de la pagina
antecesora y se fusionan las paginas que son descendientes directas
de
dicha clave.
-
La principal caracteristica de estos arboles es que todas las claves se
encuentran en las paginas hojas.
- Cualquier camino desde la raiz hasta alguna de las claves tiene la misma
longitud
-
Ocupan un poco mas de espacio que los arboles B. Este hecho es aceptable si
el archivo se modifica
frecuentemente puesto que evita la operacion de reorganizacion del arbol tan
costoso que sale en los arboles B.
-
Existe duplicidad en algunas claves
Definicion
1.
Cada pagina, excepto la raiz, contiene entre d y 2d elementos
2. Cada pagina, excepto la raiz, tiene entre d+1 y 2d+1 descendientes
3. La pagina raiz tiene al menos dos descendientes
4. Las paginas hojas todas estan al mismo nivel
5. Todas las claves se encuentran en las hojas
6. Las claves de la raiz e interiores se utilizan como indices.
Busqueda en arboles B+
-
Es un proceso similar al que se utiliza en los arboles B
- Puede ocurrir que al buscar una determinada clase esta se encuentre en la
raiz o en una pagina interior, en dado caso se continua el proceso de busqueda
por la rama derecha de dicha clave.
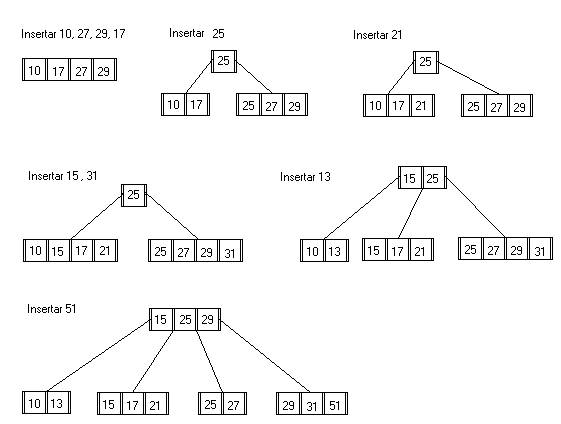
Insercion
-
Es simple y similar al proceso de insercion en arboles B
- Su grado de dificultad esta cuando debe insertarse una clave en una
pagina llena (m==2d). En este caso la pagina afectada se divide en 2 distribuyendo
las m+1 claves de la siguiente forma:
-
Las d primeras a la pagina de la izquierda
- Las d+1 claves restantes a la pagina de la derecha
- Una copia de la clave del medio sube a la pagina
antecesora
- Si la antecesora se desborda, se repite el proceso.
El proceso de desbordamiento de una pagina que no es hoja no produce duplicidad de claves, sube la clave del medio.
Insertemos los siguientes elementos en el siguiente arbol B+ de orden 2:
10-27-29-17-25-21-15-31-13-51
Asociacion estatica
Un inconveniente de la organizaci�n de archivos secuenciales es que hay que
acceder a una estructura para localizar los datos o utilizar una busqueda
binaria. La organizacion de archivos basada en la tecnica hashing permite
evitar el acceso a la estructura indice.
Organizacion
de archivos por asociacion
En este tipo de
organizacion de archivos, se obtiene la direccion del bloque de disco que
contiene el registro deseado mediante el calculo de una funcion sobre le valor
de la clave busqueda del registro. El lugar donde se pueden almacenar mas
de un registro se le denomina bucket, cuyo
tamano normalmente es un bloque de disco.
- Para insertar un registro con clave K, calculamos
una funcion h(K), lo que proporciona la direccion del bucket para ese registro.
Si existe espacio, el registro se almacena.
- Para realizar una busqueda con la
clave K, calculamos h(K) y luego se busca el bucket con esa direccion. Una
vez calculemos esa direccion, nos ubicamos en ella y comprobamos el valor
de la clave con cada registro que se encuentre en ese bucket.
- Para borrar un registro con clave
K, calculamos h(K) y eso nos da la direccion del bucket donde se encuentra.
Nos ubicamos en esta y buscamos entre los registros el que corresponda a la
clave dada.
- Asignar todos los valores de la clave de
busqueda al mismo bucket. Esta funcion no es nada deseable ya que una busqueda
tiene que examinar cada registro hasta encontrar el deseado.
- En la distribuci�n uniforme, cada bucket
tiene asignado el mismo numero de valores de la clave de busqueda dentro del
conjunto de todos los valores posibles de la clave de busqueda.
- En la distribuci�n aleatoria, cada
bucket tendr� casi el mismo numero de valores asignados a el.
Gestion de desbordamientos
de buckets
Cuando el cajon no tiene suficiente espacio, sucede lo que se denomina desbordamiento
de cajon y estos pueden ocurrir por:
-cajones insuficientes, donde el numero de ellos debe ser mayor que el numero
de registros .
-atasco, algunos cajones tiene asignados mas registros que otros por lo tanto
se podran desbordar asi otros cajones tengan aun espacio. Esto puede ocurrir
debido a que varios registros puedan tener la misma clave o porque la funcion
de asociacion produce uan distribucion irregular de las claves de busqueda.
A pesar de que controlemos en parte el desbordamiento, este aun puede ocurrir. Para esto, vamos a tratarlo utilizando cajones de desbordamiento. Si un registro se debe insertar en un bucket y este ya esta lleno, se proporciona otro cajon de desbordamiento para ese bucket y el registro se insertara en ese nuevo cajon. Si este se llena, se proporcionara otro cajon y asi sucesivamente. Todos estos cajones estan encadenados juntos en una lista enlazada. Este tratamiento se le denomina cadena de desbordamiento.
Indices asociativos
La asociatividad se puede utilizar no solamente para la organizacion de archivos,
sino tambien para la creacion de estructuras indice. Un indice hash organiza
las claves de busqueda con sus punteros asociados, dentro de una estructura
de archivo asociativo. Primero se aplica una funci�n de asociacion sobre la
clave de busqueda para identificar un cajon, luego se almacenan la clave y
los punteros asociados en el cajon.
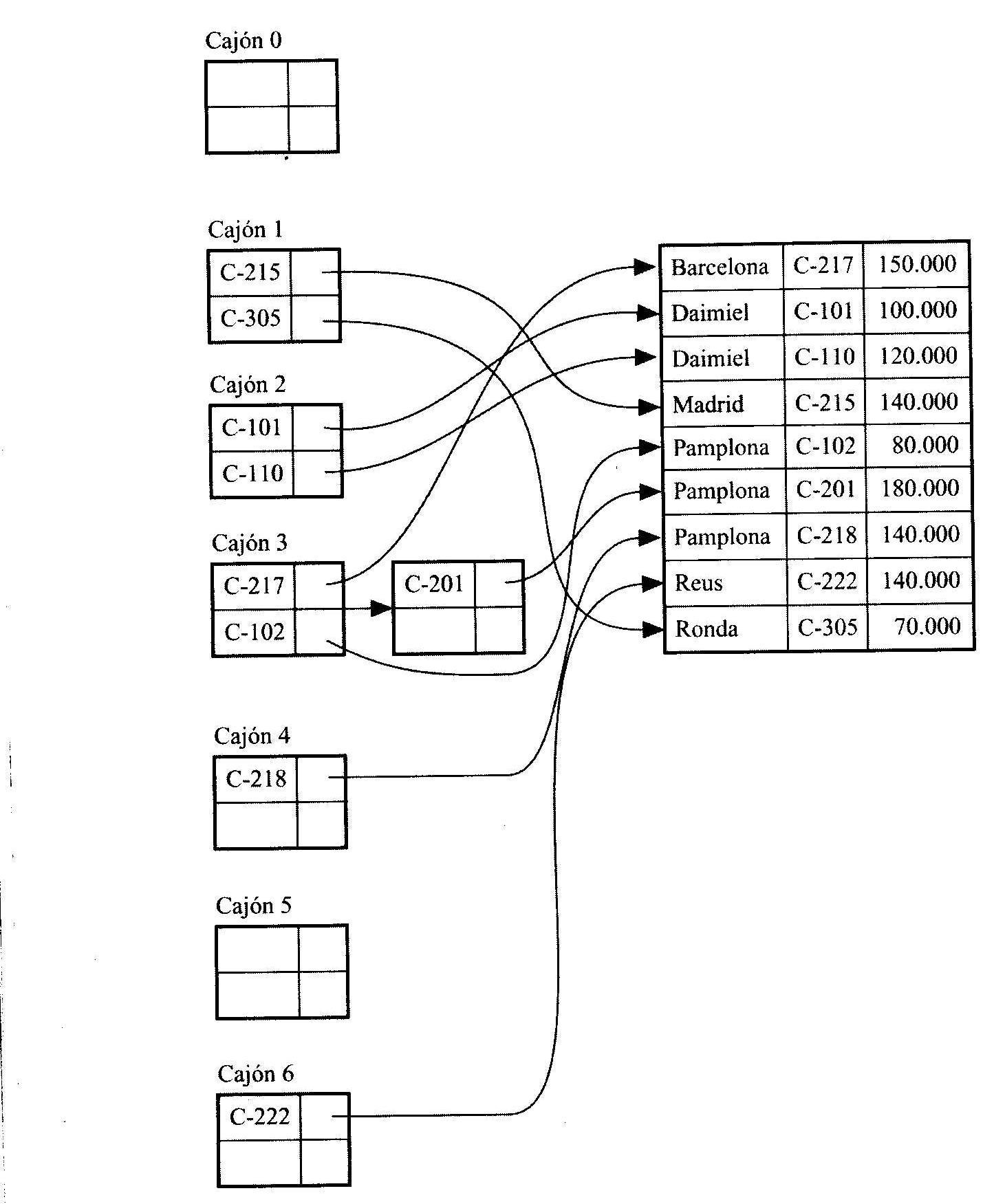
Se usa el termino indice asociativo para denotar las estructuras de archivo asociativo, asi como los indices secundarios asociativos.
Indices
en SQL
Los indices son importantes para el procesamiento eficiente de las transacciones,
incluyendo las transacciones de actualizacion y consulta. Los
indices son tambien importantes para un cumplimiento eficiente de las ligaduras
de integridad.
En principio, un sistema de bases de datos puede decidir autom�ticamente que indices crear. Sin embargo debido al coste en espacio, asi como en el procesamiento de actualizaciones, no es facil hacer una eleccion apropiada sobre que indices mantener. Por eso, la mayoria de las implementaciones de SQL proporcionan al programador control sobre la creacion y eliminaci�n de indices.
Un
indice se crea mediante la orden: create
index <nombre_indice> on <nombre_relacion> (atributos)
atributos
es la lista de atributos de la relacion que constituye la clave de busqueda
del indice.
Si deseamos declarar que la clave de busqueda es una clave candidata, hay que a�adir el atributo unique a la definicioncreate unique index <nombre_indice> on <nombre_relacion> (atributos)
Para suprimir un indice se utiliza la siguiente sentencia: drop index <nombre_indice>
Acceso
multiclave
Hasta ahora solo se ha utilizado un indice para procesar una consulta. Sin
embargo hay otras consultas en que necesitamos multiples indices.
select numero_prestamo
from cuenta
where nombre_sucursal = Pamplona and saldo = 200000;
Para realizar esta consulta podremos:
- Usar el indice nombre_sucursal --> luego se examina el
de saldo
- Usar el indice de saldo por 200000 --> luego se examina el nombre_sucursal
que cumpla con lo que queremos
- Usar un indice sucursal y el indice de saldos, se realiza una interseccion
entre los dos.
Por lo tanto, lo mas eficiente es crear un indice con clave de busqueda (nombre_sucursal, saldo).
Archivos
en reticula
- Cada celda tiene un puntero a un cajon que contiene valores de las claves
de busqueda y punteros a los registros
- Para conservar espacio se permite que varios elementos del array puedan
apuntar al mismo cajon.
Supongamos que queremos insertar un registro cuyo valor de la clave es (Barcelona, 100000000)
* Para encontrar la celda
se ubicapor separado la fila y la columna.
* Se busca en el array nombre_sucursal el menor elemento que es mayor que
Barcelona. Este es el cero ya que este se encuentra antes que el primer
elemento del vector.
* Ahora se busca en la escala lineal el saldo a ver cual corresponde a la
clave de busqueda.
* El saldo es el de la posicion 6
Como
respuesta la clave de busqueda tiene asignado la celda (0,6) de la matriz
de reticula.Por
lo tanto, accedemos a esa posicion y luego seguimos el puntero que nos lleva
a la caja donde se encuentra la informacion completa de ese registro.
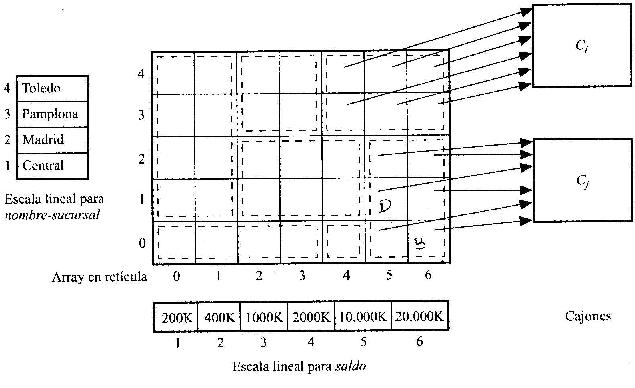
Cada celda en el array en reticula tiene un puntero a un cajon que contiene valores de las claves de busqueda y punteros a los registros. Para conservar espacio, se permite que varios elementos del array puedan apuntar al mismo cajon. Los cuadros punteados indican celdas que apuntan al mismo cajon.
Para
insertar un nuevo registro, primero se utilizan las escalas lineales para
la localizar la fila de la celda asignada a la clave de busqueda. Localizamos
el menor elemento que es mayor que el que se equiere insertar. Si la clave
de busqueda es mayor o igual que todos los elementos de la escala lineal,
se le asignara la ultima fila. Por otra parte, se realiza el mismo procedimiento
sobre la otra escala lineal para encontrar la columna que corresponde a la
clave de busqueda.

